작년에 log file parallel write wait event 가 alert에 발생하였고,
DB가 거의 마비되는 현상이 있었다.
당시 기억이 잘 나진 않지만.. session kill을 했고 redo log를 꽤 많이 추가했었다.
그리고 해당 테이블이 로그성 테이블이고 복구 포인트에서 중요도가 낮은걸 확인하였고,
담당자와 개발자분들과 협의하고 nologging으로 변경하였고 이 후 해당 메세지는 사라졌다.
============================================================================================
ALERTLOG 와 해당 시간대 AWR 확인
============================================================================================
2022-12-20T09:31:45.516237+09:00 경 발생 LG00 (ospid: 25122) waits for event 'log file parallel write' for 80 secs. . .2022-12-20T09:38:06.957128+09:00 경 해제 (was 재기동) LG01 (ospid: 25126) waits for event 'log file parallel write' for 460 secs.
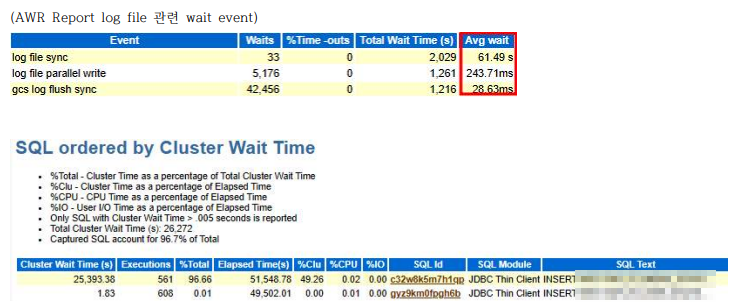
============================================================================================
log file parallel write wait event에 대한 설명
============================================================================================
●log file parallel write 이벤트는 LGWR 프로세스에서만 발생하는 대기 이벤트입니다. LGWR 프로세스는 리두 버퍼 의 내용을 리두 로그 파일에 기록하기 위해 필요한 I/O 콜을 수행한 후 I/O 작업이 완료되기를 기다리는 동안 log file parallel write 이벤트를 대기하게 됩니다. 대기시간이 길다면 리두 로그파일이 위치한 디스크의 성능이 좋지 않거나 경합현상이 발생하고 있다고 볼 수 있습니다.
●log file parallel write 대기는 I/O 관련 대기현상에서 다룬바 있는 db file parallel write 대기와 그 속성이 거의 유사합니다. 이 두 개의 대기는 근본적으로 I/O 시스템의 성능문제와 많은 관련이 있습니다. 여기에 성능문제를 바라 보는 약간의 철학적 관점이 필요한데, 가령 이런 것입니다. I/O 시스템의 성능에는 문제가 없는데도 더티 버퍼의 양이 지나치게 많은 경우 db file parallel write 대기가 증가할 수 있습니다. 마찬가지로 I/O 시스템의 성능에는 아무런 이 상징후가 없는데도 리두 데이터 양이 지나치게 많은 경우 log file parallel write 대기가 증가할 수 있습니다. 이 경우 의 성능 문제는 지나치게 많은 데이터를 생성하는 애플리케이션의 문제인지, 아니면 더욱 빠른 속도로 데이터를 처리 하지 못하는 I/O 시스템의 문제인지 알 수 없습니다. 이때, 일차적으로는 애플리케이션에서 문제와 해결책을 찾되, 더 이상의 해결책이 보이지 않을 때 I/O 시스템의 문제로 생각할 것을 권유합니다.
원인) -- '로그 파일 동기화'와 '로그 파일 병렬 쓰기' 모두에 대해 높은 대기 시간이 원인 (redo 발생량이 많다)
● IO 측면에서 LGWR의 성능을 검토해야 합니다. 일반적으로 '로그 파일 병렬 쓰기'의 평균 시간이 20밀리초 이상인 경우 IO 하위 시스템에 문제가 있음을 나타냅니다. (일반적인 시간은 디스크 캐싱 및/또는 움직이지 않는 부품이 많은 최신 스토리지 시스템의 경우 훨씬 더 짧을 수 있 음) 예: SSD, NVRAM 등)
해결방안)
● 시스템 관리자와 협력하여 IO 성능을 개선하기 위해 리두로그가 있는 파일 시스템/논리 볼륨을 검사합니다. RAID-5 또는 RAID-6과 같은 패리티 계산이 필요한 구세대 또는 덜 정교한 RAID 기술에 리두 로그 파일을 배치하지 말고 프론트엔드 캐싱 또는 버퍼링이 거의 없는 여러 디스크에 작성하고 해당 오버헤드를 마스킹하기 위한 전용 CPU 리소스를 사용하십시오. ● 이전 세대의 SSD(Solid State Disk) 기술에 리두 로그를 배치하지 마십시오.
● 일반적으로 솔리드 스테이트 디스크의 쓰기 성능은 평균적으로 양호하지만 '로그 파일 동기화'에 대한 대기 시간이 크게 증가하여 성능이 고르지 않거나 일시적인 데이터베이스 중단이 발생할 수 있는 쓰기 피크를 견딜 수 있습니다. (균등하지 않은 IO 응답 시간에도 불구하고 SSD에서 여전히 성능이 허용되는 경우가 있으므로 테스트해야 합니다.) Oracle Engineered System(Exadata, SuperCluster 및 Oracle Database Appliance)은 SSD 및 최신 관련 기술을 보다 효과적으로 활용하도록 최적화되었습니다.
● 동일한 디스크 위치 또는 일반 IO 경로에 쓸 수 있는 다른 프로세스를 찾고 스토리지 시스템에 필요한 IO 트래픽 활동을 처리할 수 있는 충분한 대역폭이 있는지 확인하십시오. 그런 다음 부하를 늘리기 위해 스토리지를 추가/현대화 하는 것을 고려하지 않으면 현재 사용 가능한 것에서 가능한 한 많이 기존 IO 활동을 처리하거나 재조정할 수 있습니 다.
● Redo 로그의 개수가 충분한지 확인이 필요하며, 스위치가 발생하는 단계에서 대기하는 리두로그가 없다면 해당 세 션은 대기하게 됩니다.
● 짧은 기간의 트랜잭션이 많은 경우 트랜잭션을 함께 그룹화하여 고유한 COMMIT 작업이 줄어들도록 할 수 있는지 확인하십시오. 각 커밋이 관련 REDO가 디스크에 있다는 확인을 받는 것이 필수이므로 커밋을 추가하면 오버헤드가 크 게 증가할 수 있습니다. 트랜잭션을 일괄 처리하여 커밋의 전체 수를 줄이는 것은 매우 유익한 효과를 가질 수 있습니 다. COMMIT NOWAIT 옵션을 사용할 수 있는 처리가 있는지 확인하십시오 NOLOGGING / UNRECOVERABLE 옵션으로 안전하게 수행할 수 있는 활동이 있는지 확인하십시오.
(참고 Troubleshooting: 'Log file sync' Waits (Doc ID 1376916.1)
이 전에 시스템 I/O 이슈도 있어서 해당 disk i/o 도 서버 담당 엔지니어에게 문의했었는데, 당시에 DB가 cubrid로 넘어가기 바로 직전이라 다들 크게 신경은 쓰지 않았다.
혹시 이런경험 있으시면 참고 하시면 될 것 같네요^^.
'Oracle' 카테고리의 다른 글
| oracle 9i to 10g upgrade 작업 (0) | 2023.07.04 |
|---|---|
| timestamp 이용하여 테이블 복구(Table recovery using timestamp) (0) | 2023.07.04 |
| archive log 보관 주기 설정(Set the archive log retention period) (0) | 2023.07.01 |
| 오라클 cpu 사용량 높은 프로세스 쿼리 조회 (How to query oracle cpu usage high process query) (0) | 2023.06.29 |
| ORACLE 로그마이너 간단한 사용법(how to use ORACLE simplely logminer) (0) | 2023.06.29 |